
What are Foundation Models?
You're already using them.

There has been a significant paradigm shift in artificial intelligence (AI) towards using foundation models. Foundation models are pre-trained machine learning models trained on vast amounts of data in a self-supervised or semi-supervised manner. These models can then be adapted and fine-tuned for various downstream tasks, allowing for highly flexible and capable AI systems to be developed with significantly less task-specific engineering.
Text Generation is a reader-supported publication. To receive new posts, consider becoming a free or paid subscriber.
The concept of foundation models represents a move from highly customized and narrowly focused AI towards more general and versatile models. In the past, an AI system designed for a specific task like image recognition or language translation needed to be built from scratch with that exact purpose in mind. Now, foundation models open up the possibility of taking a single model, pretrained on massive datasets, and specializing it for whatever application is needed.
The knowledge gained from pretraining on such self-supervised objectives transfers well to downstream tasks where less data may be available. Rather than training a model to do one thing, foundation models aim to learn generally useful representations of concepts like language, vision, and reasoning.
Examples of foundation models are LLMs, BERT, and DALL-E.
The same paradigm is now being applied to other modalities like images. Foundation models for computer vision, like DALL-E, which can generate images from text descriptions, are created by pretraining on vast datasets of image-text pairs. The model learns foundational knowledge about how language relates to visual concepts. This foundation can be adapted to downstream tasks like generating illustrations for specific prompts.
Multimodal foundation models incorporating vision, language, and other modalities into a single model are also emerging.
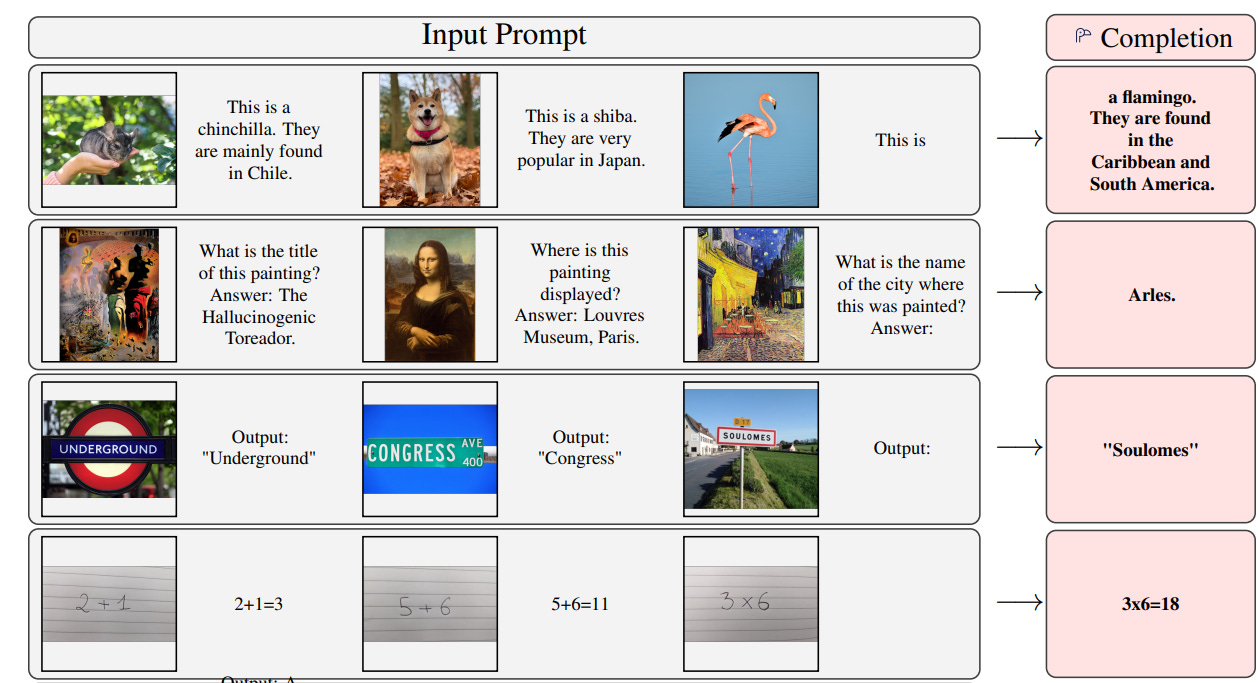
Because one foundation model can be fine-tuned for many different tasks, this approach is highly economical. The upfront computational costs of pretraining are amortized across many uses of the model. This cost efficiency incentivizes the development of large, high-quality foundation models.
However, risks are also associated with the increasing reliance on foundation models in AI systems. Because they are pretrained on such vast data, the models may implicitly encode problematic biases that get transferred downstream. Catastrophic forgetting of capabilities outside a specific fine-tuning context is also a concern. Maintaining broad capabilities while adapting to particular tasks remains an open research problem.
There are also potential pitfalls if too much standardization emerges around a small number of foundation models. This could lead to a lack of diversity in AI systems built on the same pre-trained foundations. Modeling the world from rich, multifaceted perspectives requires exploring diverse modeling approaches.
Foundation models are showing impressive generalizability. If some years ago you needed to train a text classifier with manual feature engineering, now you can fine-tune an LLM in a few lines of code. The same goes for computer vision. Building high-quality datasets for training classification or object detection models is costly and time-consuming. A multimodal LLM can do that out of the box.
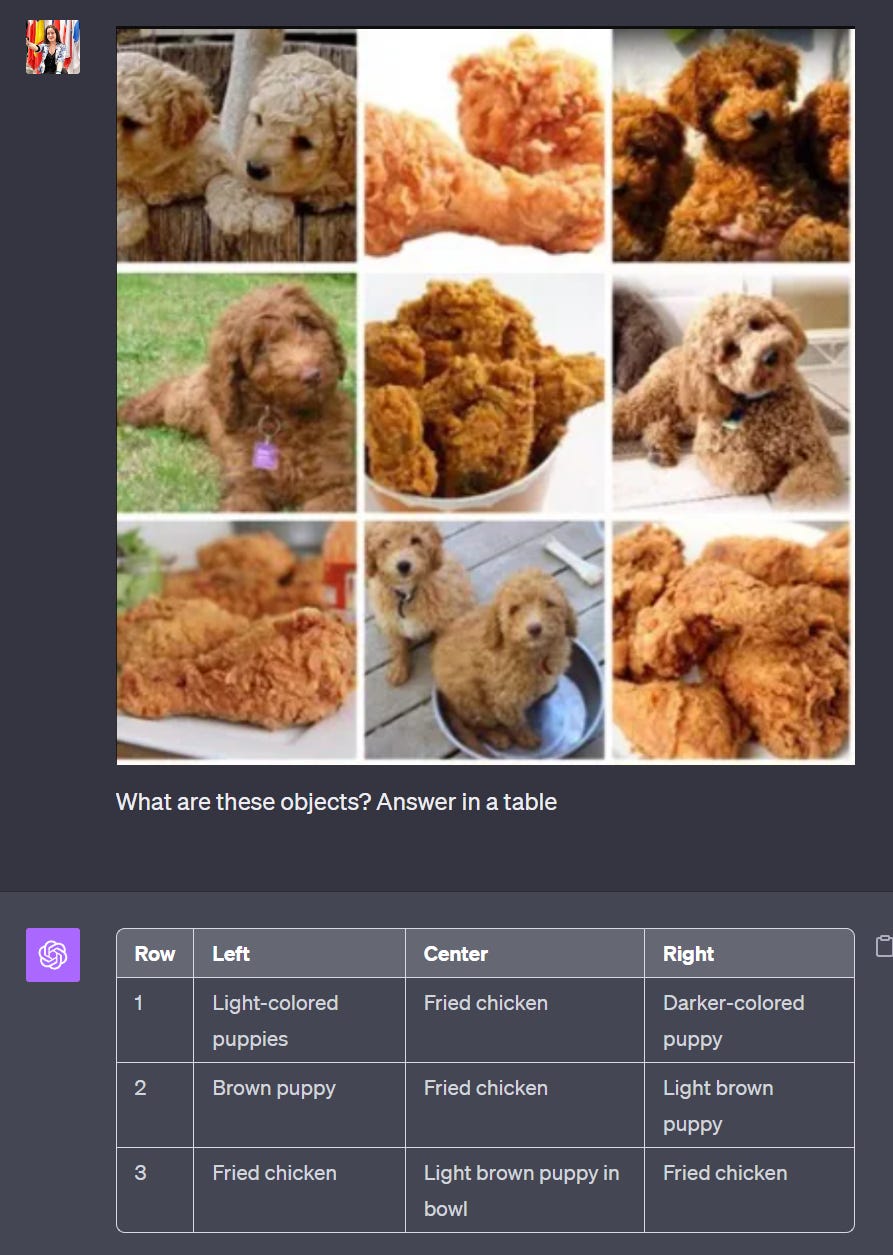
Imagine training an object detection model to perform this task well. You’d be up for taking hundreds of photos of fried chicken and puppies to get a model that can only learn these two classes. Fondation models can do that out of the box and even add details like light brown or darker colored.
Foundation models are changing the AI landscape by providing a versatile pre-trained starting point that can be adapted instead of building custom models for the task. This pretrain-then-fine-tune approach amortizes upfront costs and enables transfer learning across many downstream applications.
Thank you for reading Text Generation. This post is public, so feel free to share it and add your thoughts in the comments!
