
Rerank for Better RAG
Methods to enhance relevance and diversity in your retrievals
When building RAG applications, having access to the most relevant documents is key.
But how do we make sure that the documents we retrieve are not just topically relevant, but also diverse, non-repetitive, and optimized for the model's context window? This is where reranking comes in.
In this newsletter, we'll provide an introduction on when and how to use reranking to take your initial document retrieval results to the next level.
Text Generation is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
When to Rerank
Reranking should come after your initial retrieval round, once you've fetched an initial set of potentially relevant documents. The goal of reranking is not to find new documents, but to re-order and filter the existing ones for optimal relevance and diversity.
Some common cases where reranking helps:
- After fetching documents from a search engine. The initial ranking from these systems focuses on relevance, but lacks optimization for model context windows.
- After retrieving passages from a document store. Since they’re sorted by similarity, passages retrieved from the same document can be repetitive. Reranking promotes diversity.
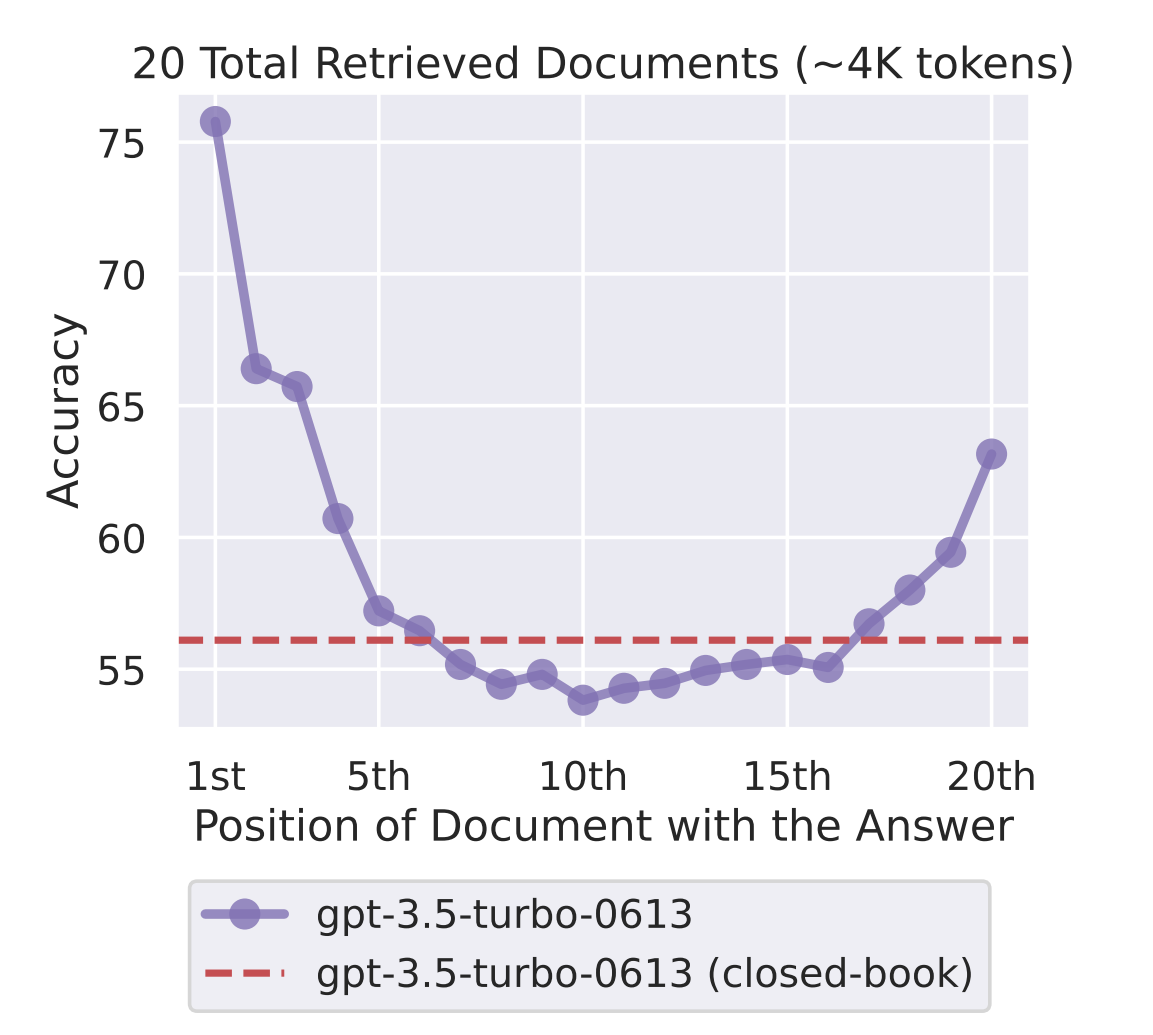
- When working with LLMs, some of them can suffer from the Lost in the middle issue. Reranking allows control over the context window content by placing the least important documents in the middle.
Re-ranking after initial retrieval allows you to optimize existing results for your model's specific needs.
Reranking Methods
There are several different approaches available for reranking documents in Haystack: [2]
- CohereRanker uses Cohere models to score documents based on similarity to the query. It considers both the query tokens and document tokens when scoring.
- DiversityRanker maximizes the variety of documents by greedily selecting the document least similar to those already chosen. This increases the diversity of results.
- LostInTheMiddleRanker positions the most relevant documents at the start and end of the list, with less relevant ones in the middle. This optimizes for the model's context window.
- RecentnessRanker scores documents by both relevance and recency. Useful for cases where newer results should be prioritized.
- SentenceTransformersRanker uses cross-encoder models to calculate similarity scores between query and documents. Can be paired with sparse retrievers like BM25 to improve ranking.
Multiple rankers can also be chained, for example first ranking by relevance with a cross-encoder, then re-ranking for diversity. This allows each ranker to focus on its own optimization criteria.
How to Add Reranking
Most libraries like Haystack provide pre-built reranking components to add to your pipeline. Here are the key steps:
- After initial retrieval, pass the results to the chosen reranker.
- Reranker will return results in the new order.
- Trim reranked results to fit your context window size.
- Pass optimized context to reader/generator model.
- Generate answers/text using improved context!
Monitor the context window content before and after reranking to validate improvements. Are results more diverse? Did relevance drop? Iteratively tweak parameters or switch up rerankers until you're satisfied.
The Takeaway
Adding reranking is an easy way to take existing retrieval results to the next level. Reranking promotes diversity and optimizes context relevance without changing the underlying corpus.
Thank you for reading Text Generation. This post is public so feel free to share it.

